Python Data Science Training In Bhopal
Classroom Training Fee: ₹3000/- per month ₹5000/- per month
Online Training Fee: ₹2500/- per month ₹4000/- per month
Course Duration : 6 Months
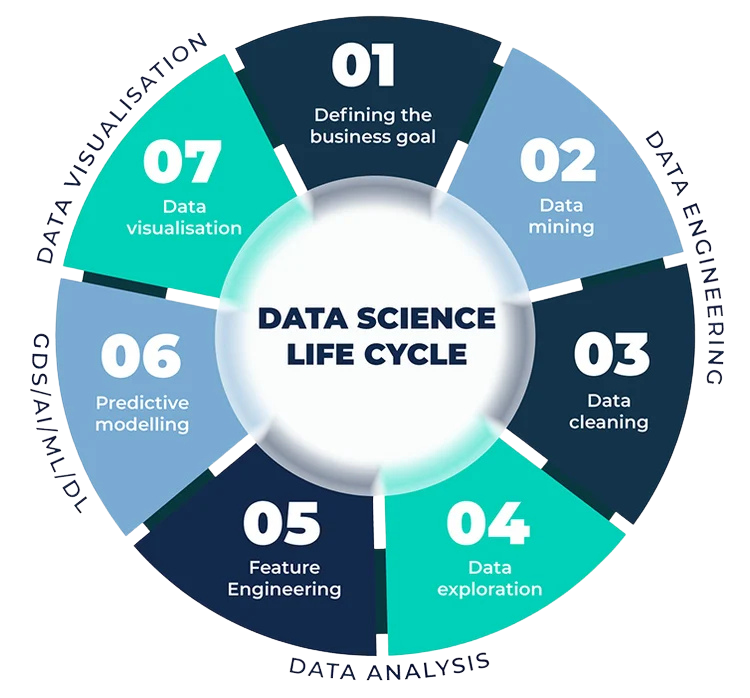
Python Data Science Course Syllabus and Curriculum For 2025
Interview Preparation & Placement Support – "Master the future of AI with real-world projects!"
Fee: ₹3000/- ₹5000/- (Classroom) | ₹2500/- ₹4000/- (Online)
| Duration: 5 Months (20 Weeks)
Class Modes: Offline & Online Classes Available
Weeks 1-4: Data Science with Python
- Week 1: Introduction to NumPy, Creating Arrays, Indexing, Slicing
- Week 2: NumPy Data Types, Copy vs View, Shape, Reshaping, Iterating
- Week 3: NumPy Array Operations: Join, Split, Search, Sort, Filter
- Week 4: NumPy Random, Data Distributions, and Seaborn
Weeks 5-8: Advanced NumPy & Data Visualization
- Week 5: NumPy ufuncs (Arithmetic, Logs, Summation, Trigonometric functions)
- Week 6: Introduction to Pandas, Series, DataFrames, Reading CSV/JSON
- Week 7: Analyzing Data in Pandas: Cleaning Data, Removing Duplicates, Correlations
- Week 8: Data Science Fundamentals, Data Preparation, DataFrames
Weeks 9-12: Data Science Concepts
- Week 9: Statistics: Percentiles, Standard Deviation, Variance, Correlation
- Week 10: Advanced Data Science: Linear Functions, Plotting, Slope, Intercept
- Week 11: Linear Regression, Regression Coefficients, P-Value, R-Squared
Course Enquiry